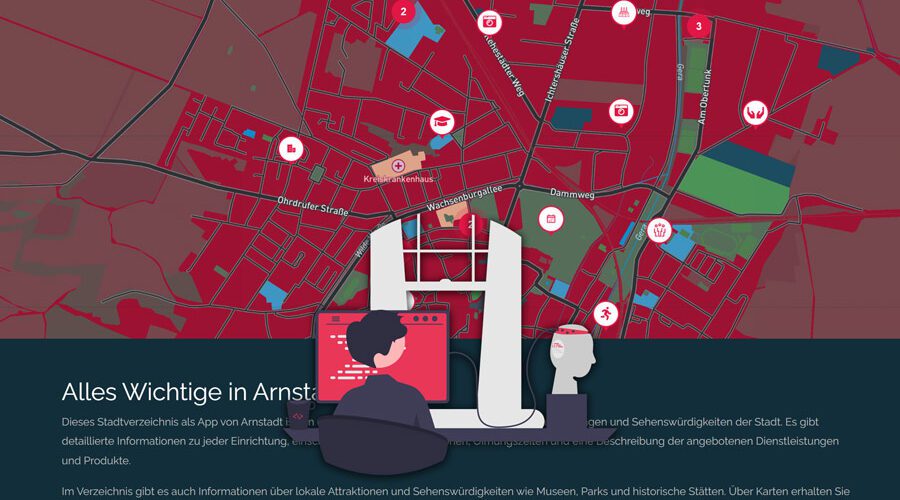
Neues Design: „BLUE LAZY PIXELS“ & KI-Update Vorüberlegungen
Mein letzter Farbflash liegt noch gar nicht so lange zurück, aber ich hatte -aus heutiger Sicht- ziemlich ins Klo gegriffen:

Ich fand das Rotbraun selbst tatsächlich nur sehr, sehr kurz wirklich toll. Ich wollte es irgendwie klassisch, aber trotzdem nicht langweilig und irgendwie »noch-nie-dagewesen«. Das Ergebnis war aber eher so „mittel“ bis „geht gar nicht“.
Der letzte Relaunch hat mich tatsächlich sehr viel Zeit gekostet. Ich hatte das CSS fast komplett neu gemacht und dieses Mal war ich hier etwas fauler. Deshalb, ich präsentiere:
inArnstadt.de jetzt mit »BLUE LAZY PIXELS« – Design
Warum ich das Design „Lazy“ (faul) genannt habe, wird ganz schnell klar, ich habe:
- alle Farben ausschließlich 1:1 durch Search & Replace geändert
- da wo das nicht so einwandfrei ging, habe ich einfach die alte Farbe gelassen
- ich war sehr effektiv im Vorgehen, da ich noch wusste, wo überall Änderungen gemacht werden müssen
Die dadurch eingesparte Zeit hab ich aber nicht für »Beine-hoch« verschwendet, ich habe für die »Hauptkarte« meinen neuen Lieblingskartenanbieter Mapbox genommen und in dessen sehr, sehr guten Design Studio auch das Design der Karte völlig neu und zu den neuen Farben passend gestaltet.

Damit wird es tatsächlich ziemlich einzigartig und das ist aus Gründen der Corporate Identity natürlich sehr sinnvoll.
Insgesamt hat es mich nicht mal ganz einen Arbeitstag gekostet und ich hoffe ganz stark, dass ich diesmal länger zufrieden bin.
KI-Update – Vorüberlegungen
Für inArnstadt.de selber steht in sehr kurzer Zeit ein KI-Update an.
Da ich hier alle Register ziehen möchte und eine perfekte, also aktuelle KI einbauen möchte, müssen hier umfangreiche Vorbereitungen getroffen werden:
- Punkt Eins hab ich schon erledigt, ich hab mich umfangreich mit KI & Urheberrecht beschäftigt und einen befreundeten Anwalt interviewt
- Da textuelles Training von KIs mit frei verfügbaren Daten vollständig durch das Urheberrecht gedeckt und durch die Informationsfreiheit geschützt ist, muss nun eine Datenbank mit Inhalten, die neuer sind als 2021 angelegt werden und in .csv, .jsons oder (erstaunlicherweise) in .pdf umgewandelt werden
- Nun folgt der Trainingsprozess. Das geht bei guter Vorbereitung fast von allein und ist je nach Umfang auch recht fix.
Es gibt aber einen Punkt, der mich noch ein wenig hadern lässt. Rechtlich ist es so, dass jeder Inhaltsanbieter durch Opt-out seinen Content entsprechend kennzeichnen kann und damit verhindern kann, dass er für KI-Zwecke verwendet wird. Das Data-Mining, so der Fachbegriff für die Datenerhebung, ist gesetzlich vollumfänglich gestattet. Aber wir sind gerade hier in Deutschland meilenweit hinter der Entwicklung hinterher und ich schätze, nicht mal viele Verlage und Onlinemedien haben entsprechende Vorkehrungen getroffen und verbieten aktiv das Sammeln Ihrer Daten.
Wenn ich jetzt also anfange Daten für meine Stadt-KI zu sammeln, geschieht die natürlich unter den entsprechenden gesetzlichen Rahmenbedingungen. Das Model, was ich mir trainiere, basiert natürlich auf einem Model von ChatGPT und auch der komplette Trainingsprozess (quasi der gesamt Technikteil) findet mit der Software und auf den Servern von OpenAI statt oder aber sehr unwahrscheinlich bei Microsoft Azure.
Es ist wohl sicher unstrittig, dass beide Anbieter zwangsläufig erkennen (müssen), wer per Opt-out das scannen verbietet.
Einerseits
Wer in Arnstadt und Umgebung hat denn überhaupt bereits Vorkehrungen getroffen, seine Inhalte vor dem Zugriff durch die KI zu schützen? Ich glaube: NIEMAND.
Jetzt stehe ich also vor dem Dilemma etwas zu tun, was völlig klar erlaubt ist, aber ich doch etwas tue, was der eine oder andere vielleicht nicht möchte und eben noch nicht aktiv widersprochen hat.
Andererseits
Tut das, was KI macht, jeder Journalist, Wissenschaftler oder Blogschreiber auch, nur eben sehr langsam, analog und ohne fotografisches Gedächtnis. Natürlich liest jeder Journalist, was andere schreiben. Recherche ist wesentlicher Teil der Arbeit von Journalisten oder auch Wissenschaftlern.
Konklusion
Entschieden habe ich noch nichts, aber der Einsatz und das Training ist doch sehr wahrscheinlich und hier bitte ich jeden, der nicht möchte, dass seine Daten in die »Fänge« der KI kommen, entsprechende Vorkehrungen auf seiner Website zu treffen, damit OpenAI die Daten nicht verarbeitet.
Es bringt übrigens überhaupt 0,nix, wenn Sie mir das sagen und ich Ihre Website nicht scannen soll. Die Robots von OpenAI sind längst unterwegs, um selbst aktuelle Daten in ihren Index aufzunehmen. Der aktuelle für alle verfügbare Index wird sicher zeitnah so oder so auf diese Daten aktualisiert. Zusätzlich lässt sich ChatGPT schon jetzt mit Plugins mit dem Internet verbinden und kann somit auf aktuelle Information zugreifen. Natürlich werden die so gewonnen Daten weiter verarbeitet und gespeichert.
Jetzt handeln
Sie sollten also jetzt handeln, wenn Sie nicht in den KI Index wollen. Ich persönlich halte das aber für die allermeisten Websites nicht für zielführend, denn alles, was auf Websites veröffentlicht wird, ist ja dafür gedacht gelesen zu werden und damit muss es zwingend auch vorher verarbeitet werden. Ohne Katalog, findet mensch auch in einer Bibliothek kein Buch.
Ob nun Google die Inhalte scannt und speichert oder OpenAI ist sicher nicht allzu sehr relevant für die meisten. Trotzdem sollte das jeder selbst entscheiden können.
Hier auf inArnstadt.de werde ich wohl noch ein paar Tage warten. Vielleicht schreibt mir ja jemand privat. Aber ganz ehrlich, ich bin auch mega gespannt auf die technische Umsetzung. Gern_
Fazit
inArnstadt.de bleibt am Puls der Zeit. Das neue Design soll vor allen gefallen und ansprechend sein. Nicht ganz unwichtig ist, dass die App an sich jetzt völlig »unique« ist und die ungewollte Ähnlichkeit zu Diensten gleicher Natur abgelegt hat. Ob sie im Endeffekt nützlich ist, oder doch nur eine Abklatsch von irgendwas, entscheiden Sie! Schauen Sie gern im Blog vorbei.

